While I was at the Higher Technical College, a few colleagues and I developed a Chat application. At the time I was just getting started learning about Microservices-Architecture and the related patterns. As I wanted to apply what I was learning I figured why not build a Microservices-Backend for the chat app? In this post I want to share the mistakes I made designing the system and purpose an architecture of what I think a scalable chat backend could look like given the ability to use modern technologies. So without further ado, here’s the original architecture:
The original architecture
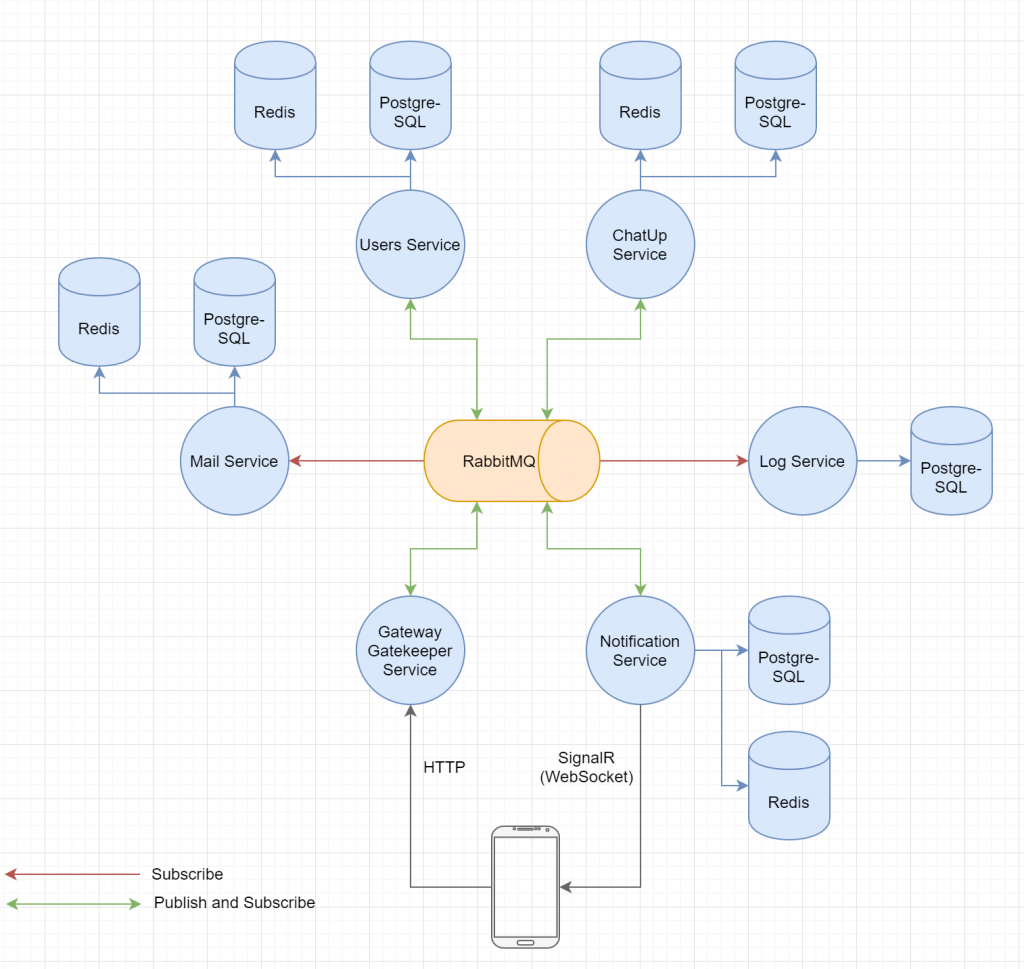
The mobile app talked to the backend via HTTP and received push notifications using SignalR (a .NET technology for real-time communication). All inter-service communication was done using AMQP, specifically the RabbitMQ broker. Along with that, every service that needed to persist data had it’s own database (PostgreSQL) and where it made sense a cache (Redis). The Gateway Gatekeeper service was responsible for validating requests and basically acted as the API Gateway (for the most part, we’ll get to that). When users signed up, they received a verification code via email and it was the Mail services’ job to manage the process and validate the codes entered at signup by the users. The User service was quite simply responsible for managing users (so mostly CRUD for user entities). It also notified the other services when something changed in the user database. A special feature of the app was that you could basically chat someone “up”. Users had tags and this feature would connect people with similar interests. That was the responsibility of the ChatUp service. The Log service was used to do just that, logging. Last but not least, the Notification service was responsible for managing the connections from the clients and to send push notifications.
Doesn’t look to bad, I guess? Well we did some things right, the services were somewhat autonomous and every service had it’s own database and cache. Anyway, let’s talk about what went wrong/should have been done differently:
- The Gateway Gatekeeper service should have been responsible for push notifications as well. This design kind of defeated the point of having an API Gateway because clients had to connect to 2 different endpoints in the end
- Use the right tool for the job. We used AMQP for everything, including Request/Response. Using HTTP would have been way simpler, especially because we were using ASP.NET Core (.NET Web Framework) anyway. We could have used SSE as well instead of SignalR, since we only needed push notifications. The reason we went with SignalR was to be able to use it’s scale out capabilities to be able to replicate the service without having to implement the logic to share sessions across instances ourselves
- Don’t write a Log service (or literally any service related to a cross-cutting concern). Their are amazing tools out there, like the ELK/EFK Stack, that are way better at doing just that. Furthermore, they are available for free, so unless you have a really solid reason to do so, use what’s available. Other cross-cutting concerns can likely be handled by your API Gateway, such as authentication and authorization. Which brings me onto the next point
- The whole User service shouldn’t exist, just like the Log service and Notification service. An API Gateway can and is actually supposed to take responsibility of managing authentication and authorization
- The anti-pattern of Nano-Services was our biggest mistake. Some service had literally less than 20 classes and the overhead of managing inter-service communication was huge. The architecture would have been just as scalable if we had kept it to down to like 3 services
- Tipp: Don’t use Microservices as a tool for scalability. Microservices are about much more then enabling applications to scale, which was our biggest intention for using them (basically we wanted to design a highly-scalable chat backend). If scalability is your main concern then you should look elsewhere (like the actor model)
So I hope this will help you avoid the mistakes we made when designing our scalable chat backend. Now, let’s look at how I would design the system now, applying what I’ve learned. The new architecture is scalable, highly-available and evolvable:
The new architecture
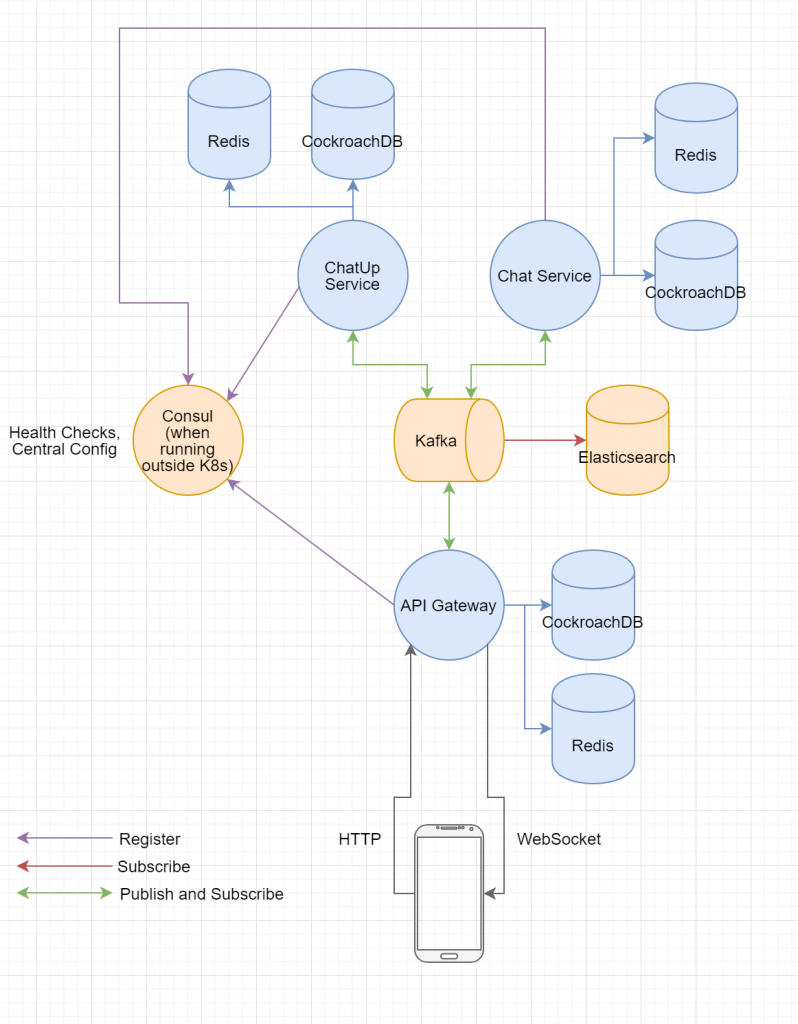
Explanation:
- The new architecture contains 3 services. The API Gateway is responsible for user management, authentication, authorization and push notifications. All traffic hitting the backend goes through the API Gateway. Logic regarding the actual chat functionality is managed by the Chat Service, e.g. checking if a user has been blocked by the receiver before sending the message or in general determining who receives which messages. The ChatUp Service remains unchanged
- All synchronous communication has been removed. HTTP requests start actions and results are delivered over WebSocket push notifications. This way there is no need for Circuit Breakers or other resilience methods, and the ChatUp Service and Chat Service can act as workers and be freely replicated (Competing Consumers)
- CockroachDB instead of PostgreSQL. Replicating services becomes pointless once your database becomes the bottleneck, thus a NewSQL Database made with distribution in mind suits our architectural needs better
- Kafka instead of RabbitMQ. Kafka serves 2 purposes here, it persists the log messages generated by the services and delivers them to Elasticsearch where they can be easily queried and analysed. You now also have the option to plug in Kibana for visualization. Along with that Kafka also acts as the message broker for asynchronous inter-service communication. Though from what I’ve read I think Apache Pulsar might be worth considering aswell
- Introduction of Consul (or Kubernetes). You need some component to check whether your service are still alive and well in a Microservices-Architecture, otherwise you might end up with lots of dead services without noticing. I personally like Consul because it can take care of health checks alongside service registration and centralized configuration while being quite easy to configure. Although when running on Kubernetes it can take care of those things for you, so you don’t need an additional component like Consul. Services’ health will be monitored by one of these components and configuration will be received from a central place. Further, since services register themselves (or are registered in the case of Kubernetes), you can easily get an overview of what’s going on in your system using these tools
As you can see, by avoiding Nano-Services, using the right tool for the job and rethinking the services’ responsibilities we ended up with a much easier, yet more scalable and highly-available architecture. Furthermore, you can plug in Kafka Stream processors or ETL services talking to Kafka and CockroachDB to add analytics or machine learning to your application. New services can enhance the existing system without having to worry about synchronous communicating hindering performance. Thus the architecture is evolvable aswell.
What do you think about this new architecture? I hope you could learn a thing or two from the mistakes that we made and the new architecture i purposed. If there was something you liked/disliked or you’ve got some type of application you’d like to see me design, let me know. I’m highly looking forward to your feedback!
0 Comments