For some time I’ve been playing around with the idea of developing an API to offer Sentiment Analysis as a Service, like major cloud providers are already doing. In this blog post I’m going to share how I would design such a system.
Before we jump right into the architecture, let’s talk a bit about what the service would offer. My idea would be to give users the ability to choose between different sentiment analysers, each offering it’s own set of advantages and disadvantages. So you could have one that trades speed for accuracy and vice-versa. Further, users would be able to combine different sets of analysers to best suit their use case (basically offering an aggregate analyser). Clients would sign in with an account and be billed based on how much text they analysed each month and what analysers they used. The API would be contacted using HTTP, which presents a challenge because we’ve now got synchronous communication at the edge and that requires some measurements to be taken in order for the architecture to still be scalable, evolvable and highly-available. Enough explanation for now, let’s have a look at how I’d design such a system:
The architecture
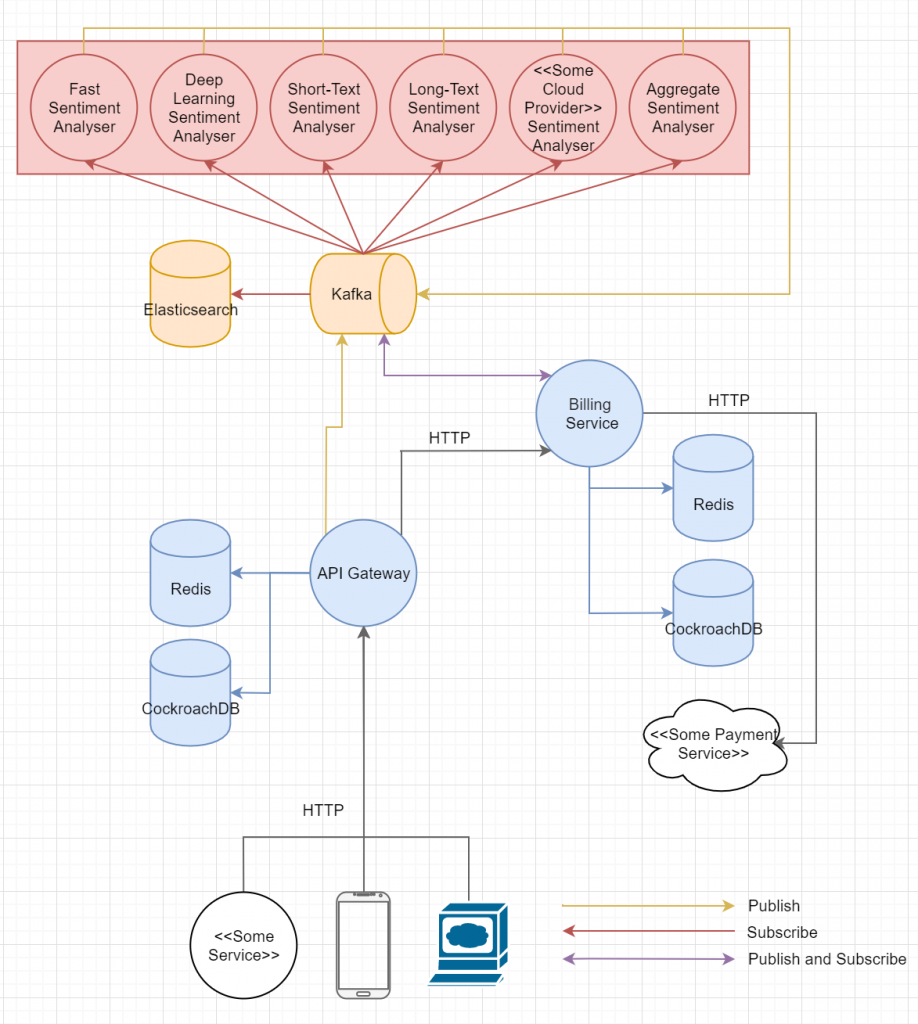
Explanation:
- The red circles represent Spark Structured Streaming jobs.
- Anyone (be it a mobile app, some other service or a web app) wanting to use the service talks to the API Gateway via HTTP. It’s responsible for managing users, authentication and authorization and it forwards requests to the Billing Service. Any changes in the user database are published to Kafka by this service.
- The Billing Services’ is responsible for tracking how much users use the service and billing them accordingly. Besides that, it basically coordinates individual requests. When a users wants some text to be analysed, the billing service checks that all necessary details are available and the user can be billed. Only then does it publish a message to Kafka which is distributed according to the selected analysers to one or more Spark Structured Streaming jobs. These analyse the actual text and write the result back to Kafka. The Billing Service aggregates the results and calculates an updated amount to be billed by the next billing date. Finally, it returns the result back to the API Gateway and further to the user.
- Once it’s time for billing, the service talks to an external payment service.
- In order to guarantee the services autonomy, the Billing Service has it’s own database which it updates based on events published to Kafka by the API Gateway.
- The Billing Service holds onto requests from the API Gateway. As a result, the instance that kicked off a analysis request must be the instance that returns back the response. That’s why all instances receive all messages and check whether they are part of a aggregation for one of their requests or not. Think of it as a fan-out exchange in RabbitMQ terms. While this is sub optimal it is necessary in order to provide a synchronous interface to the service for users (HTTP). From a pure technical standpoint, delivering results to the client using WebSocket and having them kick off requests using HTTP POST would be the best option, with the downside of it complicating the flow for clients. If you want to go for the latter route, I’d strongly consider offering client libraries for the most common programming languages in order for your service to be easily accessible.
- The API Gateway uses resilience patterns like the Circuit Breaker to ensure it doesn’t wait for responses indefinitely (aka block forever).
- CockroachDB was chosen instead of more classical databases like MySQL or PostgreSQL because it’s been built from the ground up with distribution in mind, which allows for easily scaling the database once it becomes the bottleneck while still offering ACID guarantees and a familiar SQL interface (plus it’s PostgreSQL compatible, meaning you can use available PostgreSQL drivers for your programming language)
- Redis acts as a caching layer to lighten the load on the database by minimizing direct access to it.
- The architecture diagram assumes that the whole application is run in Kubernetes. This implies that it takes care of service discovery and load balancing (for the API Gateway to contact the Billing Service) as well as centralized configuration (by supplying environment variables to the services) and health checking. An alternative would be to use Consul as shown in the previous blog post (though you know have to implement some sort of client-side load balancing).
- All logs are written to Kafka and forwarded into Elasticsearch for easy analysis. This further allows plugging in additional components, e.g. Kibana for visualization.
- Let’s talk a bit about the actual analysers available. My idea was offering one focused on speed (Fast Sentiment Analyser), which would use something like Pythons TextBlob library, one based on Deep Learning techniques (e.g. some RNN architecture and one of the options available to run TensorFlow on Spark), one optimized for short/long texts respectively, multiple analysers providing an interface over the ones from major cloud providers and an aggregate analyser for choosing any combination of analysers. There are endless possibilities here, you can make up your mind about what could make sense.
The architecture was designed to allow every component to be either distributed or replicated and horizontally scaled, which results in an highly-available and scalable architecture. What about evolvability? As in the previous blog posts’ design, one could easily plug in Kafka Stream processors or ETL services talking to Kafka and CockroachDB to add advanced analytics to the application. Other than that new services can subscribe to anything going on in the broker and enhance the systems functionality. The only part that would need to be adjusted is the API Gateway in order to allow access to the new functionality. That’s one disadvantage of using an API Gateway, although I think it’s worth it most of the time because it seriously simplifies things on the clients end. Other than that, Kafka allows services to access literally everything that has ever happened in the system (since we’ve introduced a form of Event Sourcing in the architecture by communicating data asynchronously via Kafka, which keeps a log of the messages published to it). This opens up endless possibilities of types of analysis to be done (e.g. see what type of text is being analysed the most, what is the average length of a text,…).
What do you think about this design? Let me know your thoughts in the comments below. I’d love to get feedback from you. Hope to see you soon!

0 Comments